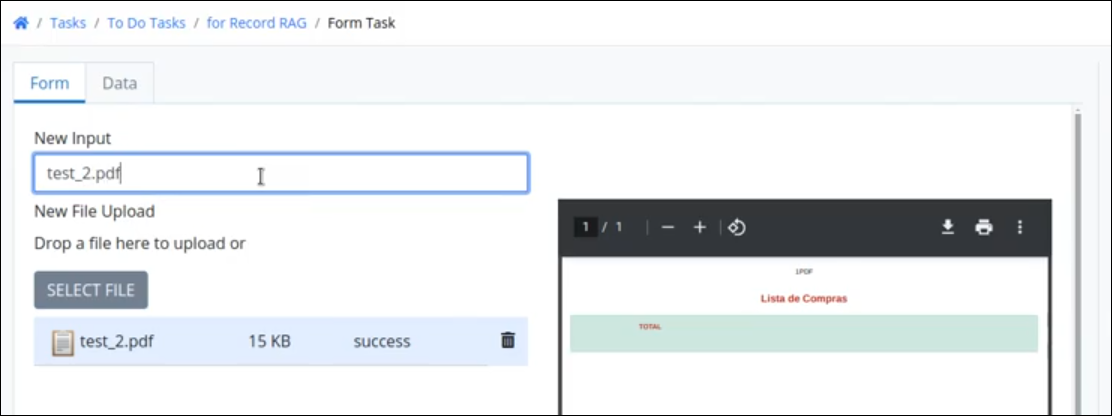
Add Files to a RAG Collection from a Process
Follow these steps to add files to a RAG collection from a process.
Prepare Process Variables
From your process, ensure you have the following variables:
File ID – The variable name of the uploaded document (e.g.,
file_id).File Name – The name to assign to the file when saved in the collection (e.g.,
file_name).
Create a REST Data Connector
After creating a REST Data Connector, set up a REST Data Connector using the Bearer Token authentication method.
Provide a valid Bearer Token to authenticate the connection with your ProcessMaker instance.
.png)
Create a Resource in the Data Connector that uses the following API endpoint for collections:
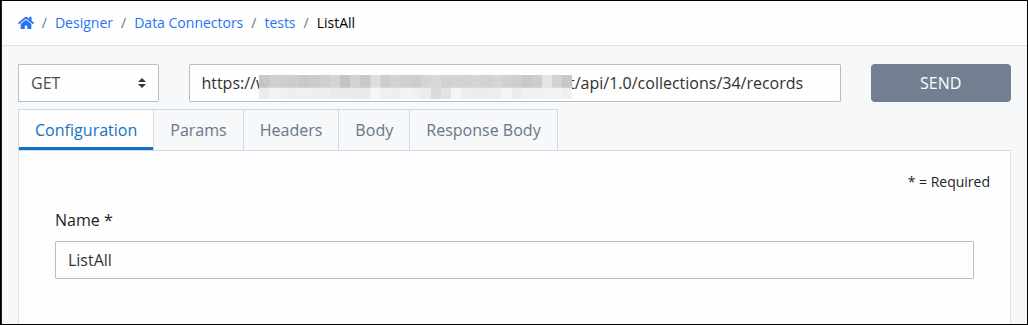
https://{server_name}/api/1.0/collections/{collection_id}/records
Replace
{collection_id}with the ID of your target RAG Collection.
In the Body of the Resource, use the following JSON structure:
.png)
{
"data": {
"file": "{{file_id}}",
"name": "{{file_name}}",
"uploads": [
{
"id": "{{file_id}}",
"name": "{{file_name}}"
}
],
"source_type": "file"
}
}Add a Data Connector Task
Insert a Data Connector Task in your process, ensuring it comes after the file is uploaded and the file-related variables are populated.
Configure Outbound Parameters
Map the process variables to the connector resource in the task's Outbound Configuration:
file_id→{{file_id}}file_name→{{file_name}}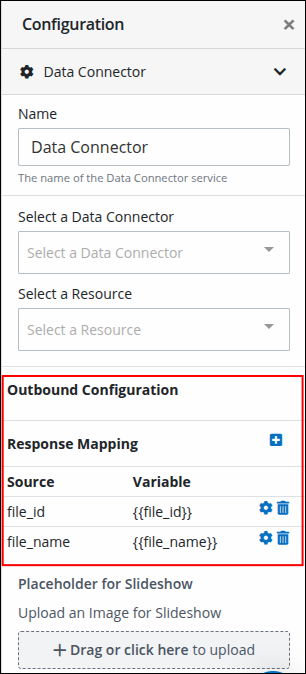
Result
Each time a case runs, the Data Connector will automatically insert the uploaded file as a new record in the RAG Collection, triggering the appropriate analysis.
To send the
file_namefield to the Data Connector, make sure to enter the full file name including the file extension (e.g.,document.pdf,invoice.docx).